


作者 | kingly
来源 | Github
来源:微信微信官方账号:知识小集
出处:https://mp.weixin.qq.com/s/a1mPjrw0EBupSacQLVly5Q
01 理论
iOS随着各种事件的曝光,应用安全越来越受到重视。那针对iOS应用安全能做些什么?如何让我们开发的应用更安全?要知道如何安全,就要知道iOS为什么应用不安全?现在,随着越狱技术的改进和各种工具的改进,逆向分析iOS应用已经成为一件容易的事情。所以,要做的iOS应用更安全,从逆向工程的各个阶段层层阻挡。当然,这只是增加逆向难度~。
iOS逆向分析分为静态分析和动态分析。分析的前提是有一个越狱设备,然后应用去壳,使用工具去壳后的应用 class-dump导出文件(先泄露,本文针对它,哈哈~),用于分析程序逻辑和设计实现,并使用它IDA 或Hoper反汇编。以上两种方法是静态分析。利用LLDB动态调试验证应用,这种方法是动态分析。逆向的事情不多说(就知道这些-_-|),本文的设计是为了增加导出头文件分析的难度,让逆向人员看着头文件,两眼冒金星~~
为达到一眼两眼冒金星的效果,现计划混淆以下内容:
1.文件名
2.类名
3.协议名
4.属性名
5.函数名
你觉得袁芳怎么样?混淆上述内容后,编译发布。这样使用 class-dump导出的第一个文件也应该混淆。这也达到了我们的目的。
混淆的方式是什么?混淆只不过是将原始单词解释的关键字变得不可读,这很简单,直接调用系统本身md5加密算法可以加密。
混淆很简单。混淆似乎指日可待~
混淆原理:提取上述需要混淆的关键词,然后md加密,然后更换工程中的关键字。
原则很简单,应该考虑哪些问题?
1.如何提取关键字?
2.混淆算法很简单,这不是问题…
3.混淆替换混淆后的原始关键字?
4.混淆后的项目还会恢复吗?
5.如何实现混淆程序?
…
1.如何提取关键字?
提取关键字,当然,根据各种关键字自身的特点,使用工具自动完成提取。手动提取并不疯狂!!!如果工具提取,包括系统在内的所有符合规定的关键字都会被提取出来吗?这个程序还能被编译吗?也就是说,提取关键字,只能提取自定义,不能提取系统本身生成或使用。这有点麻烦~~~。
2.混淆算法
md5.这是不可逆转的,所以混淆后要保留关键词和加密后的对应表,以便后续排除bug用。
3.混淆替换混淆后的原始关键字?
当然,这是用工具批量更换的。遇到以下情况怎么办?
原字符串:This is my fish.” 要将is” 替换为”is not。当然,我们希望的是:This is not my fish.” 而不是“This not is not my fis noth.” 。也就是说,要达到预期的目的,必须是单词匹配替换,这是非常重要的。
4.混淆后的项目还会恢复吗?
能混淆,当然能还原,但似乎没必要哦~~,那就不考虑还原了,我的地盘听我的,呵呵。
5.如何实现混淆程序?
首先当然是脚本,命令行工具丰富,可以用。可惜要一个个学。
还有什么场景?没了就开始整个~
02 实现
针对设计描述的一般思路,现在针对各个问题点给出实现方法
脚本大致使用的工具如下:vi、grep、sed、find、awk、cut、sort、uniq、cat、md5等。
对于要加密的内容,给出关键字提取脚本命令。
脚本中 $ROOTFOLDER 代表工程根目录, $EXCLUDE_DIR 代表排除的目录如下:
ROOTFOLDER="demoProject" EXCLUDE_DIR="–exclude-dir=*.framework –exclude-dir=include –exclude-dir=libraries –exclude-dir=Libs –exclude-dir=lib"关键字提取1.文件名
第一步是将包含路径的文件名写入文件
find $ROOTFOLDER -type f | sed "/\\/\\./d" >f.list
第二步提取文件名称
cat f_rep.list | awk -F/ '{print $NF;}'| awk -F. '{print $1;}' | sed "/^$/d" | sort | uniq
但从文件名提取的功能来看,上述两个步骤可以完全合并为一个步骤,但在实际功能实现中,上述步骤仍需分为两个步骤
2.类名
grep -h -r -I "^@interface" $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]' | sed "s/ /" |awk '{split($0,s," ");print s[2];}'|sort|uniq
其中sort,排序;uniq 去除重复。
3.协议名
grep -h -r -I "^@protocol" $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]'| sed "s/[\\<,;].*$//g"|awk '{print $2;}' | sort | uniq4.属性名
grep -r -h -I ^@property $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]' | sed "s/(.*)/ /g" | sed "s/<.*>//g" |sed "s/[,*;]/ /g" | sed "s/IBOutlet/ /g" |awk '{split($0,s," ");print s[3];}'|sed "/^$/d" | sort |uniq
其中
sed "/^$/d"
去除空行。
5.函数名
grep -h -r -I "^[-+]" $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]' |sed "s/[+-]//g"|sed "s/: *\\^\\/\\{]/ /g"|sed "s/[ ]*</</"|awk '{split($0,b," ");print b[2];}'| sort|uniq |sed "/^$/d"|sed "/^init/d"
目前,函数名提取只是提取函数名第一段的名称,如:
-(void)funName:(NSString *)param1 secondParam:(NSString *)param2;
然后脚本只会提取funName。脚本中
是函数中的以 init因为,oc默认情况下,初数init`一开始,如果混淆了这种函数,就会有问题。
然后,上述脚本可以收集各种关键字,合并成文件,然后重复排序。
小小结
从上述脚本中提取的关键字包括系统本身和我们自己添加的关键字。如果所有这些都被混淆了,那么我们混淆的程序肯定无法运行,甚至无法通过编译。那我们该怎么办?这个问题是设计文章中提出的麻烦多事。最容易想到的方法是判断关键词是否是系统自用的。如果是,就不要混淆,而是混淆。系统如何使用哪些关键字?很简单,就是用上面提到的脚本提取系统使用的关键词,作为系统自用的保留词。这个问题可以通过排除来解决。虽然笨拙,但有效。
所以第一步是制作一个系统来保留字典库。可以用上述脚本完成。
第二步是提取要替换的关键字。如果你仔细看上面的脚本,你会发现一个问题。提取文件名时,提取所有文件名,包括排除的目录。因此,这个地方会有问题。提取文件名时,应排除排除的目录或将排除的目录文件名作为临时保留字。
过滤和加密保留字
过滤上述两个步骤获得的关键字。
cat $SOURCECODEKEYWORDS | while read line do if grep $line $RESKEYSALL then echo filter1: $line else md5 -r -s $line | sed s/\\"//g >> $REPLACEKEYWORDS fi done
其中$SOURCECODEKEYWORDS是从ROOTFOLDER提取要混淆的关键词
更换工程中的关键字
这一步是本功能的核心。为了实现文件中的关键字替换,这是错误的。准确地说,它应该是文件中的关键字替换。这是设计文章中提到的问题。
愿字符串:"This is my fish.” 要将is” 替换为”is not“。当然,我们想要的是:This is not my fish.” 而不是“This not is not my fis noth.” 。也就是说,要达到预期的目的,必须是单词匹配替换,这是非常重要的。实践证明,OS X版的sed单词匹配替换没有实现,只能用字符串替换匹配正则表达式行,即替换后是我们不想要的结果。这可肿吗?幸运的是,经过一番挖掘,找到了一种笨拙的方法,效果如下,又要发挥愚公的精神。
sed -i '' ' '"$v2"'s/)'"$var2"':/)'"$var1"':/g '"$v2"'s/('"$var2"':/('"$var1"':/gn '"$v2"'s/ '"$var2"':/ '"$var1"':/gn '"$v2"'s/\"'"$var2"':/\"'"$var1"':/gn ' $v1 n
其中,v2代表行号;var2代表要替换的关键字,即例子中的“is”;var1是混淆后的字符串;v1 是指文件路径,包括文件名;-i表示直接修改文件,后面必须带两个单引号,要不然会有错误,单引号内容应该是要备份的文件名,在此不需要备份所以为空;在第一行和最后一行之间的意思是,描述单词出现时的各种场景,要想达到单词匹配的效果,那就在此必须列举所有情景,这个真够蛋疼的~~,愚公上吧!!!
替换属性设置方法
cat repProperty.txt |n while read linen do n ar=(`echo "$line"|cut -f 1-2 -d " "`)n first=`echo ${ar[1]}|cut -c -1| sed "y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/"`n second=`echo ${ar[1]}|cut -c 2-`n lastFind=`echo set$first$second`n lastRep=`echo setZ${ar[0]}m`n rm -f rep.tmpn if grep -r -n -I -w "$lastFind" $ROOTFOLDER $EXCLUDE_DIR –include="*.[mhc]" –include="*.mm" –include="*.storyboard" –include="*.xib" >rep.tmpn then n cat rep.tmp |n while read ln do n v1=$(echo "$l"|cut -d: -f 1 )n v2=$(echo "$l"|cut -d: -f 2 )n sed -i '' ''"$v2"'s/'"$lastFind"'/'"$lastRep"'/g' $v1 n echo "step3:"$l n done n else n echo "step3:do not find:"$lastFind n fi n done n
这个也是相对比较麻烦的,因为oc的属性系统是可以自动合成setter函数的,所以属性的混淆需要额外多考虑点。上面的做法是,根据提取的过滤后的属性关键字,生成属性设置函数,然后查找过程中是否有用到,有就混淆掉。
文件名混淆
cat f_rep.list |n while read linen don echo "old name:"$line n v1=$(echo "$line" | sed "s/\// /g" | awk '{print $NF}')n echo "v1="$v1 n v2=$(echo $v1 | sed "s/\./ /g" | awk '{print $1}')n echo "v2="$v2 n if grep -w $v2 $RESKEYSALL n then n echo "find." n else n v3=$(echo $v1 | sed "s/\./ /g" | awk '{print "."$2}')n echo "v3="$v3 n v4=$(md5 -q -s "$v2" | sed "s/.*/z&m/g")n echo "v4="$v4 n v5=$(echo "$line" | sed "s/"$v1"//g")n echo "v5="$v5 n mv $line $v5$v4$v3 n echo "new name:"$v5$v4$v3 n fin donen
文件名混淆的原理就是将需要混淆的文件路径,提取出要混淆的部分,然后组合成最终的文件名,使用mv命令完成文件名混淆。
至此,设计篇中提及的要混淆的内容已经全部完成混淆。
注意事项
1.需要将工程名称作为临时保留关键字
如:工程名称demoProject,那么demoProject要作为保留字,否则混淆后,可能target的名称也会被混淆掉,这个不是我们期望的;
2.需要将工程中的子目录名称作为临时保留关键字
如:在工程目录下有子文件夹AFNetworking,在Xcode工程的导航里也可以看到AFNetworking的分组,此时,如果AFNetworking也被混淆,那么工程中的分组会变成混淆后的字符串,但是工程目录下的子文件夹AFNetworking并没有改变,所以此时,会找不到响应的文件;根本原因是我们的混淆没有对文件夹名进行混淆。
3.需要将访问网络时组织的参数名称作为临时保留关键字
如:有一个属性名为:passport;恰好在组织网络参数时,有一个字段也叫passport,如果作为属性关键字passport被混淆了,那么组织网络参数时用的passport也会被混淆掉,所以此时传给后台的关键字passport就变了,导致后台无法识别;因此,出现这个情况时,要添加到临时的保留字中;如果编码规范的话,不用添加临时保留字也会避免~
4……
03 使用
全部 KYConfuse.sh ,实现代码如下:
#!/bin/bashnecho "#########################################"necho "File Name:KYConfuse.sh "necho "Copyright (c) 2018 KYConfuse"necho "Email:362108564@qq.com"necho "Create:2018.05.28"necho "#######################################"necho "用户修改区-开始"n#要替换的源代码所在的根目录,该脚本文件与根目录处于同级文件夹nROOTFOLDER="KYSecurityDefenseDemo"n#要排除的文件夹,例如demo中用到的第三方库AFNetworking,pods的第三方库等nEXCLUDE_DIR=" –exclude-dir=Pods –exclude-dir=buildAppstore –exclude-dir=Carthage –exclude-dir=Images.xcassets –exclude-dir=Assets.xcassets –exclude-dir=Certificates –exclude-dir=fastlane –exclude-dir=fastlanelog"necho "用户修改区-结束"nn#自定义的保留关键字,相当与白名单,添加到该文件中,一行一个,加入该文件的关键字将不被混淆;如工程中自定义的文件夹名称nRESCUSTOM="resCustom.txt"nn#保留关键字文件不可删除nRESERVEDKEYWORDS="./reskeys.txt"n#最终的保留关键字=保留关键字+文件名nRESKEYSALL="./reskeysall.txt"n#提取的所有关键字nSOURCECODEKEYWORDS="./srckeys.txt"n#过滤后,最终要替换的关键字,混淆结束后,不删除,用于bug分析nREPLACEKEYWORDS="./replacekeys.txt"nn#删除已经存在的临时文件nrm -f $SOURCECODEKEYWORDSnrm -f $REPLACEKEYWORDSnrm -f $RESKEYSALLnrm -f temp.resnn#提取文件名列表nrm -f f.listnfind $ROOTFOLDER -type f | sed "/\/\./d" >f.listn#根据要排除的文件目录,将文件列表分离n#Exclude=$(echo $EXCLUDE_DIR | sed "s/–exclude-dir\=//g" |sed "s/ $//g" | sed "s/[*.]//g" | sed "s/ /\\\|/g")nExclude=$(echo $EXCLUDE_DIR | sed "s/–exclude-dir\=//g" |sed "s/ $//g" | sed "s/ /\\\|/g")n#保留文件列表nrm -f f_res.listncat f.list | grep "$Exclude" >f_res.listn#混淆文件列表nrm -f f_rep.listncat f.list | grep -v "$Exclude" >f_rep.listnrm -f f.listn#提取文件名nrm -f filter_file.txtncat f_rep.list | awk -F/ '{print $NF;}'| awk -F. '{print $1;}' | sed "/^$/d" | sort | uniq >filter_file.txtnn#从源代码目录中提取要过滤的函数关键字nrm -f filter_fun.txtngrep -h -r -I "^[-+]" $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]' |sed "s/[+-]//g"|sed "s/[();,: *\^\/\{]/ /g"|sed "s/[ ]*</</"|awk '{split($0,b," ");print b[2];}'| sort|uniq |sed "/^$/d"|sed "/^init/d" >filter_fun.txtnn#从源代码目录中提取要过滤的属性关键字nrm -f filter_property.txtngrep -r -h -I ^@property $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]' | sed "s/(.*)/ /g" | sed "s/<.*>//g" |sed "s/[,*;]/ /g" | sed "s/IBOutlet/ /g" |awk '{split($0,s," ");print s[3];}'|sed "/^$/d" | sort |uniq >filter_property.txtnn#从源代码目录中提取要过滤的类关键字nrm -f filter_class.txtngrep -h -r -I "^@interface" $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]' | sed "s/[:(]/ /" |awk '{split($0,s," ");print s[2];}'|sort|uniq >filter_class.txtnn#从源代码目录中提取要过滤的协议关键字ngrep -h -r -I "^@protocol" $ROOTFOLDER $EXCLUDE_DIR –include '*.[mh]'| sed "s/[\<,;].*$//g"|awk '{print $2;}' | sort | uniq >>filter_class.txtnn#合并要过滤的关键字,并重新排序过滤nrm -f $SOURCECODEKEYWORDSncat filter_fun.txt filter_property.txt filter_class.txt filter_file.txt |sed "/^$/d" | sort | uniq >$SOURCECODEKEYWORDSnrm -f filter_fun.txtnrm -f filter_class.txtnrm -f filter_file.txtnn#自动获取保留字,工程名等nrm -f temp.resncat `cat f_rep.list | grep project.pbxproj` | grep -w productName | sed "s/;//g"|awk '{print $NF;}'>temp.resn#提取要保留的文件名ncat f_res.list | awk -F/ '{print $NF;}'| awk -F. '{print $1;}' | sed "/^$/d" | sort | uniq >>temp.resnrm -f f_res.listn#合并自定义保留字n#判断自定义保留字文件是否存在,不存在即创建一个空的nif [ ! -f "$RESCUSTOM" ]; thenntouch "$RESCUSTOM" nfincat $RESERVEDKEYWORDS $RESCUSTOM temp.res | sort |uniq >$RESKEYSALLnrm -f temp.resnn#过滤保留字,将需要混淆的关键字加密后写入文件nrm -f $REPLACEKEYWORDSncat $SOURCECODEKEYWORDS |nwhile read linendonif grep $line $RESKEYSALLnthennecho filter1: $linenelsen#使用md5对关键字进行加密nmd5 -r -s $line | sed s/\"//g >> $REPLACEKEYWORDSnfindonenrm -f $SOURCECODEKEYWORDSnn#开始混淆,替换源代码中的关键字为加密后的,防止开头为数字的情况ncat $REPLACEKEYWORDS |nwhile read linendonvar1=$(echo "$line"|awk '{print "z"$1"m"}')nvar2=$(echo "$line"|awk '{print $2}')nrm -f rep.tmpnif grep -r -n -I -w "[_]\{0,1\}$var2" $ROOTFOLDER $EXCLUDE_DIR –include="*.[mhc]" –include="*.mm" –include="*.pch" –include="*.storyboard" –include="*.xib" –include="*.nib" –include="contents" –include="*.pbxproj" >rep.tmpnthenncat rep.tmp |nwhile read -r lndon#获取文件路径nv1=$(echo "$l"|cut -d: -f 1 )n#获取行号nv2=$(echo "$l"|cut -d: -f 2 )n#获取指定行数据nv3=$(sed -n "$v2"p "$v1")n##sed自带文件文本替换功能,不符合我们的期望,故放弃使用;有无适合的脚本命令,还希望脚本高手予以指点~n#sed -i '' ''"$v2"'s/'"$var2"'/'"$var1"'/g' $v1n#特殊字符转义替换,echo中 输出的变量 一定要加双引号!!!nv4=$(echo "$v3" | awk '{gsub(/"/, "\\\"", $0);gsub(/</, "\\\<", $0);gsub(/>/, "\\\>", $0);gsub(/\*/, "\\\*", $0);gsub(/\//, "\\\/", $0);gsub(/\[/, "\\\[", $0);gsub(/\]/, "\\\]", $0);gsub(/\{/, "\\\{", $0);gsub(/\}/, "\\\}", $0);gsub(/\&/, "\\\\\&", $0); print $0;}')n#单词替换nvar3=$(./KYReplacewords.run "$v4" "$var2" "$var1")n#整行替换nsed -i '' "$v2"'s/.*/'"$var3"'/g' "$v1"necho "step2:$l"ndonenelsenecho "step2:do not find:$var2"nfindonenrm -f tmp.txtnn#过滤保留字,用于属性设置函数混淆,将需要混淆的关键字加密后写入文件nrm -f repProperty.txtncat filter_property.txt |nwhile read linendonif grep $line $RESKEYSALLnthennecho filter1: $linenelsenmd5 -r -s $line | sed s/\"//g >> repProperty.txtnfindonenrm -f filter_property.txtnn#开始混淆,替换属性前带下划线的地方ncat repProperty.txt |nwhile read linendonar=(`echo "$line"|cut -f 1-2 -d " "`)nlastFind=`echo _${ar[1]}`nlastRep=`echo _z${ar[0]}m`nrm -f rep.tmpnif grep -r -n -I -w "$lastFind" $ROOTFOLDER $EXCLUDE_DIR –include="*.[mhc]" –include="*.mm" –include="*.storyboard" –include="*.xib" >rep.tmpnthenncat rep.tmp |nwhile read lndonv1=$(echo "$l"|cut -d: -f 1 )nv2=$(echo "$l"|cut -d: -f 2 )nsed -i '' ''"$v2"'s/'"$lastFind"'/'"$lastRep"'/g' $v1necho "step3:"$lndonenelsenecho "step3:do not find:"$lastFindnfindonenrm -f rep.tmpnn#开始混淆,替换属性设置函数ncat repProperty.txt |nwhile read linendonar=(`echo "$line"|cut -f 1-2 -d " "`)nfirst=`echo ${ar[1]}|cut -c -1| sed "y/abcdefghijklmnopqrstuvwxyz/ABCDEFGHIJKLMNOPQRSTUVWXYZ/"`nsecond=`echo ${ar[1]}|cut -c 2-`nlastFind=`echo set$first$second`nlastRep=`echo setZ${ar[0]}m`nrm -f rep.tmpnif grep -r -n -I -w "$lastFind" $ROOTFOLDER $EXCLUDE_DIR –include="*.[mhc]" –include="*.mm" –include="*.storyboard" –include="*.xib" >rep.tmpnthenncat rep.tmp |nwhile read lndonv1=$(echo "$l"|cut -d: -f 1 )nv2=$(echo "$l"|cut -d: -f 2 )nsed -i '' ''"$v2"'s/'"$lastFind"'/'"$lastRep"'/g' $v1necho "step3:"$lndonenelsenecho "step3:do not find:"$lastFindnfindonenrm -f rep.tmpnrm -f repProperty.txtnncat f_rep.list |nwhile read linendonecho "old name:"$linen#获取文件名,带后缀nv1=$(echo "$line" | sed "s/\// /g" | awk '{print $NF}')necho "v1="$v1n#获取文件名,不带后缀nv2=$(echo $v1 | sed "s/\./ /g" | awk '{print $1}')necho "v2="$v2nif grep -w $v2 $RESKEYSALLnthennecho "find."nelsen#获取后缀nv3=$(echo $v1 | sed "s/\./ /g" | awk '{print "."$2}')necho "v3="$v3n#对不带后缀的文件名加密nv4=$(md5 -q -s "$v2" | sed "s/.*/z&m/g")necho "v4="$v4n#获取路径nv5=$(echo "$line" | sed "s/"$v1"//g")necho "v5="$v5n#修改文件名nmv $line $v5$v4$v3necho "new name:"$v5$v4$v3nfindonennrm -f f_rep.listnrm -f $RESKEYSALLnnecho "########################### 恭喜您,代码混淆完成!###########################"necho "########################### 运行混淆后的工程!###########################"nnexitn
在终端执行,切换到 KYConfuse.sh 所在目录,执行脚本
# ./KYConfuse.shn
即可,混淆工程的文件名,类名,协议名,属性名,函数名的混淆。
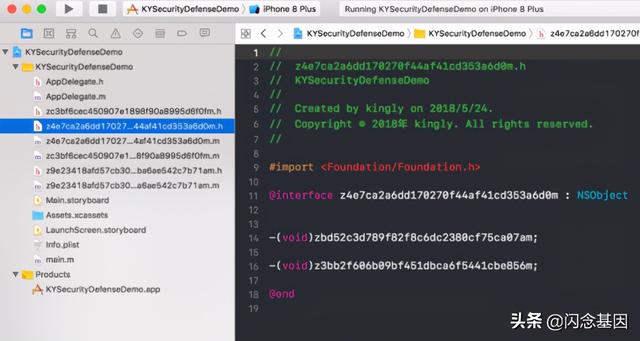
混淆后的工程如下:
作者 | kingly
来源 | Github
来源:微信公众号:知识小集
出处:https://mp.weixin.qq.com/s/a1mPjrw0EBupSacQLVly5Q
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至827202335@qq.com 举报,一经查实,本站将立刻删除。文章链接:https://www.eztwang.com/dongtai/51759.html
 微信扫一扫
微信扫一扫 
