
文本处理实际上是一个大话题,不能用文本处理这个名字来概括,从这一章开始,我们直接用子项目名称来命名。
关键词:HTML代码
让我们开始从网页代码的文本文件中提取文本的新内容。网页代码,我们通常称之为他html代码。
下面我们有一个文本文件,内容如下


内容很长,我们只拿出一个屏幕,可以做例子。
下面的话题是从这个代码文件中提取要看的内容。为此,我们编写一个程序进行练习。该程序的名称是从网页代码中提取的文本.py》。
先做第一件事,不做任何修改,直接读取文本文件的内容。
所以我们编写了以下程序
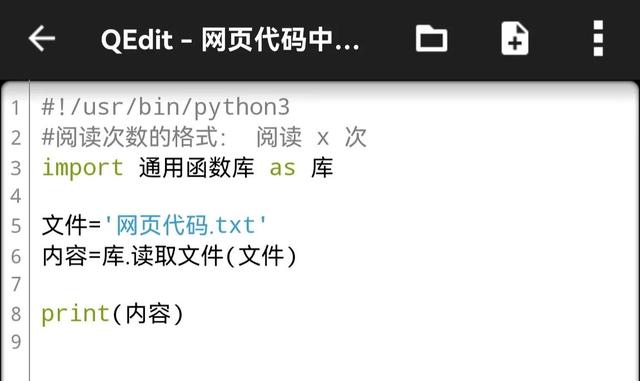
读过前一篇文章的人一眼就能理解这个程序,不用再解释了。运行后,显示效果如下
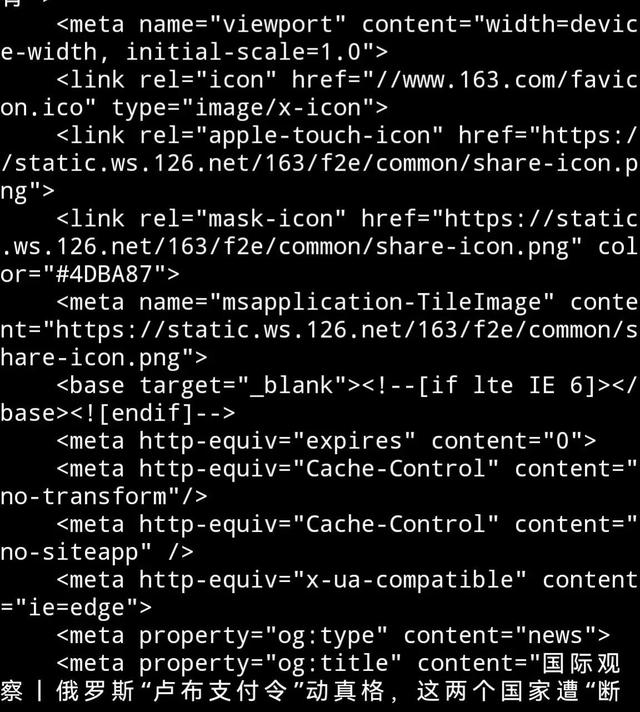
我相信很难从这个代码中读出中文内容。
下面研究的主题是选择中间有用的中文部分,删除其他代码部分,尽量保持应该保持的段落。最后,如果条件允许,处理内容,最后保持文章的主要部分。简而言之,如何处理更多的内容?
首先,我们将研究第一个问题,了解网页代码的基本知识。
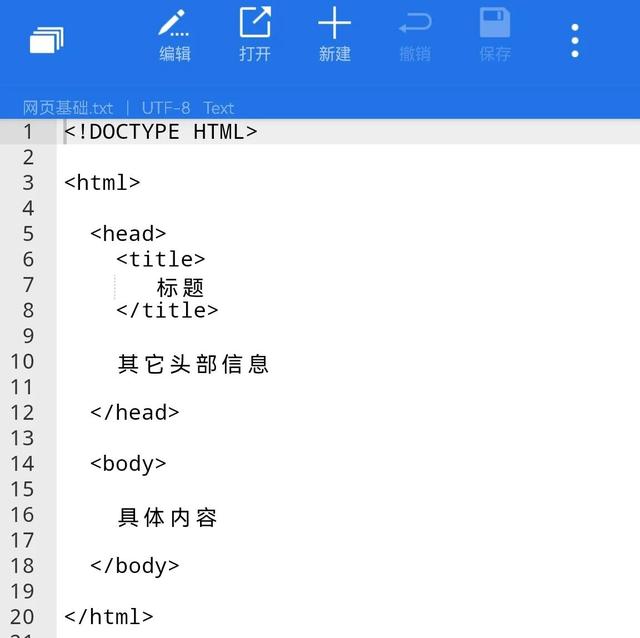
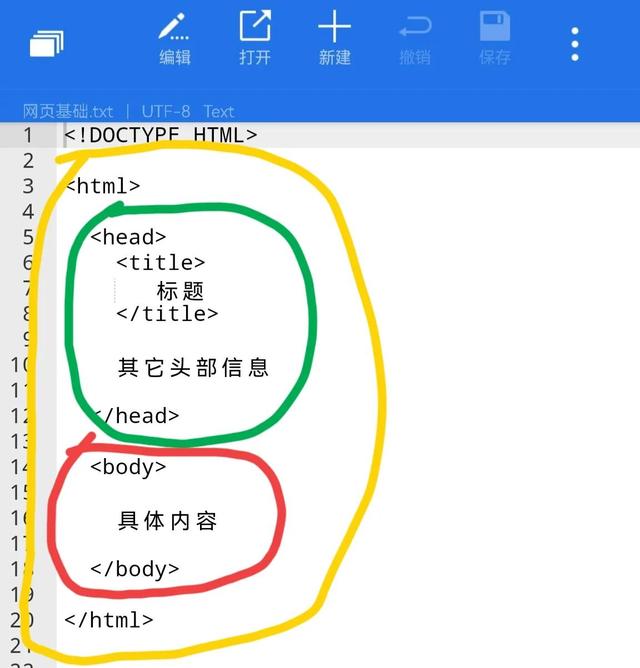
第一张图片是网页的基本框架。在第二张图片中,我们标记了它。绿色部分是网页的头部信息,红色部分是网页的实质性内容。黄色圆圈是网页的所有代码。
网页的代码通常用尖括号标记,有许多特殊符号,如下
<html></html>这两个是匹配的,中间是网页代码的具体内容。
<body></body>这两个也是匹配的,中间是代码中文章内容的具体部分。
<p></p>这两个也是匹配的,中间是文章段落的具体部分。
HTML语言,大部分内容都是这样匹配的,有些不匹配。
因为内容太多,我们只做最简单的介绍。只要你掌握了一个规则,代码通常用尖括号包含。
需要注意的是,我们可以随意打开网页,查看源代码。我们研究的是通过提取文本内容来研究文本处理的方法。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至827202335@qq.com 举报,一经查实,本站将立刻删除。文章链接:https://www.eztwang.com/dongtai/51908.html
 微信扫一扫
微信扫一扫 
